
Why AIOps Is Key to Cyber Threat Detection in Defense?...
Read More
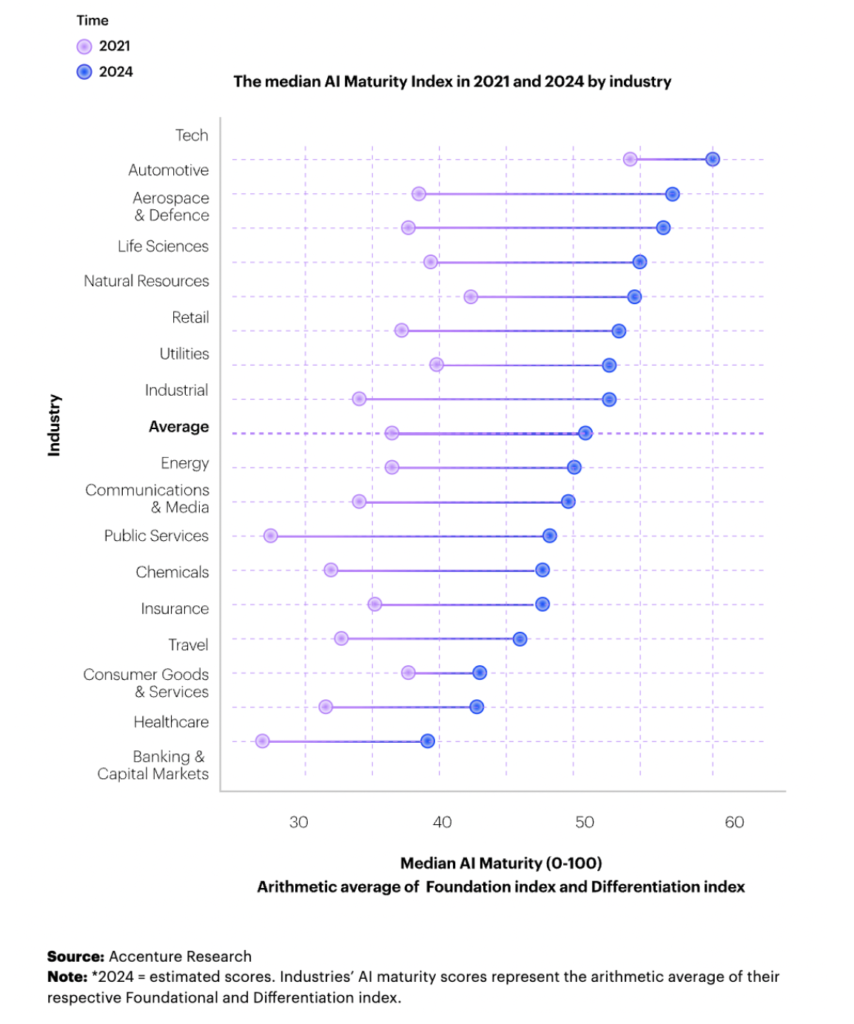
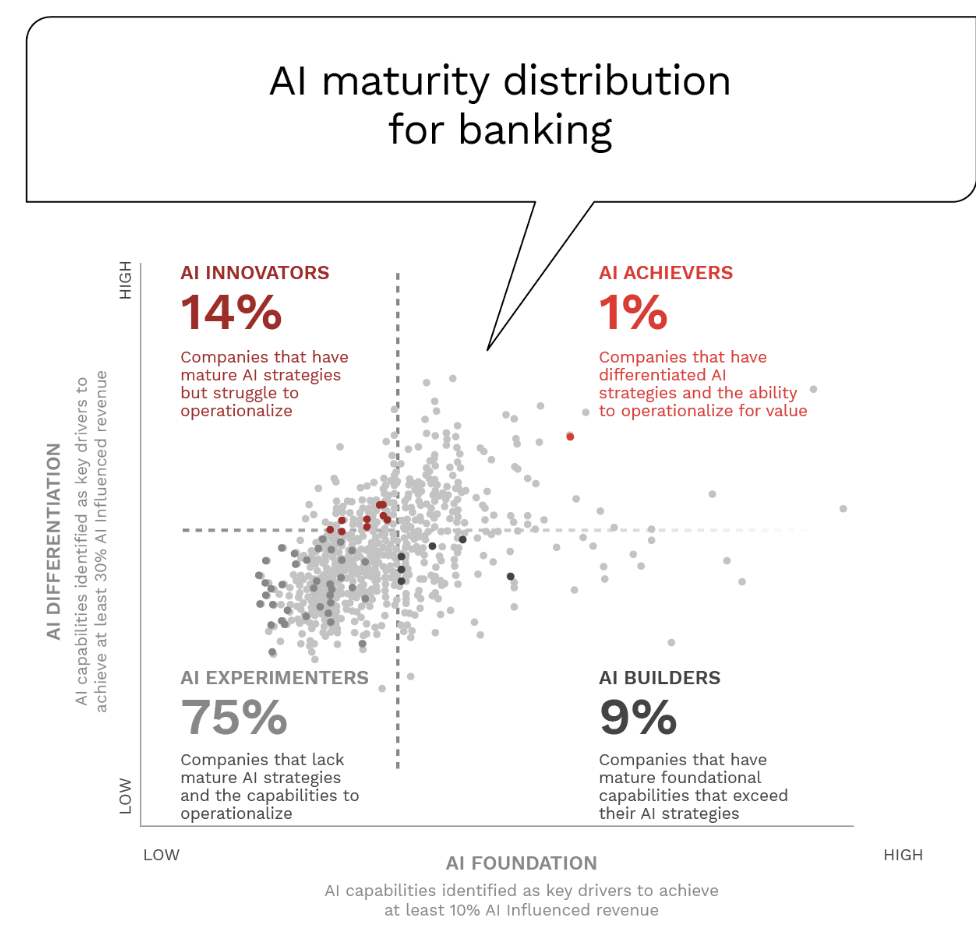
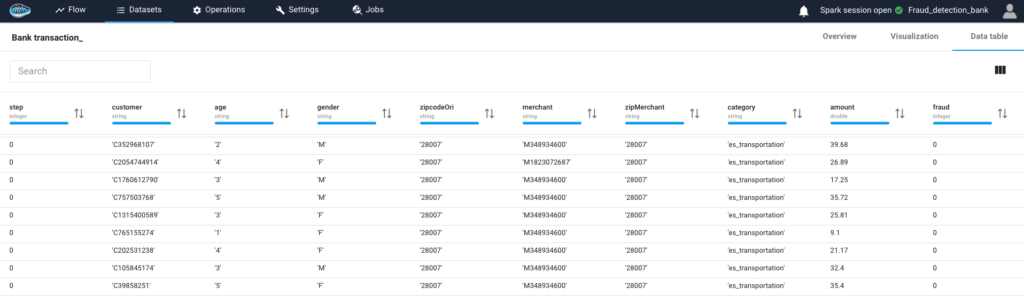
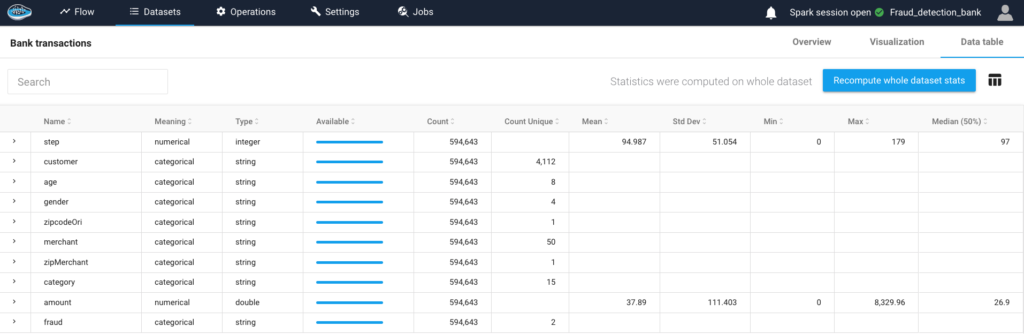
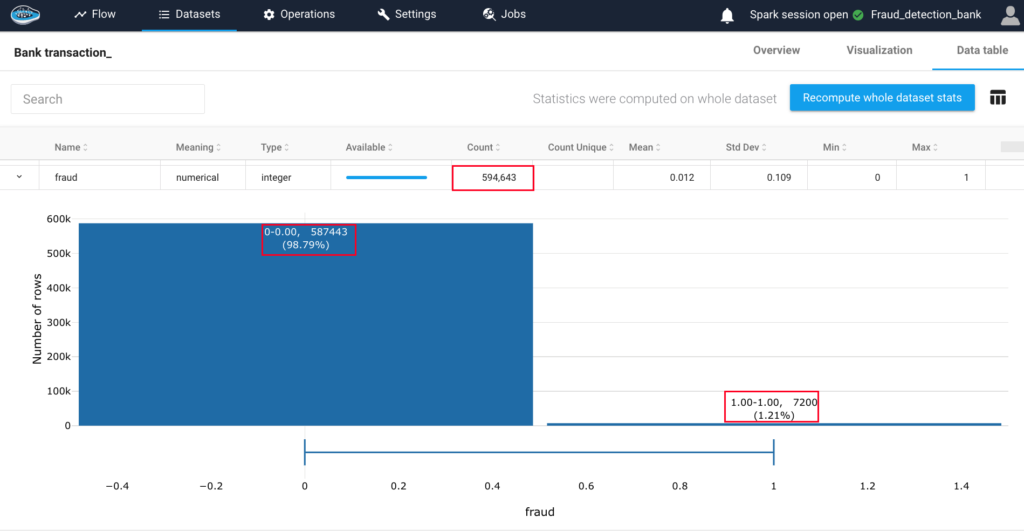
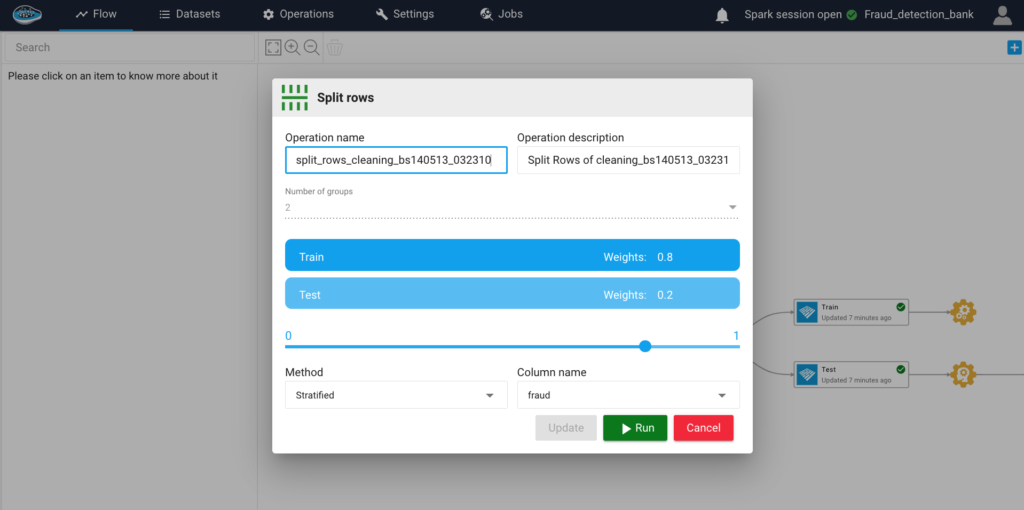
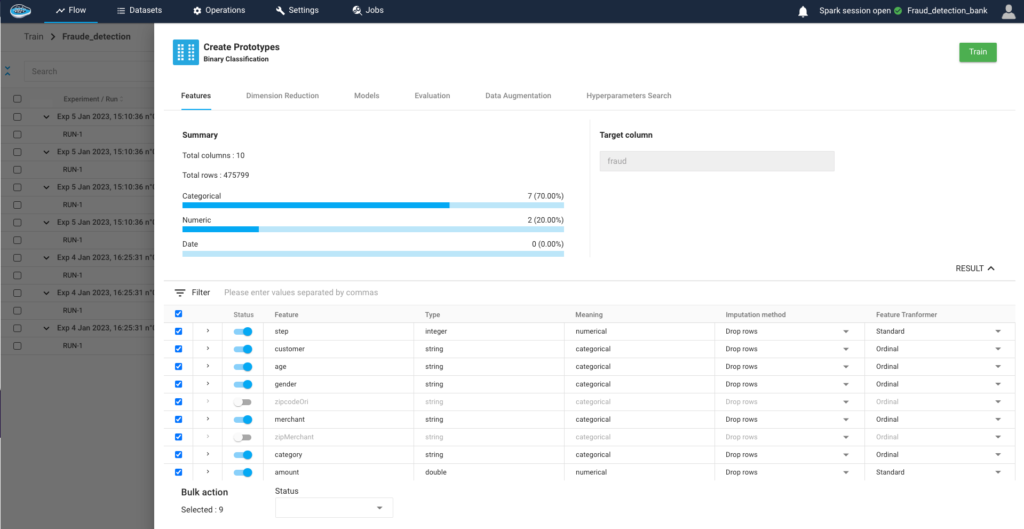
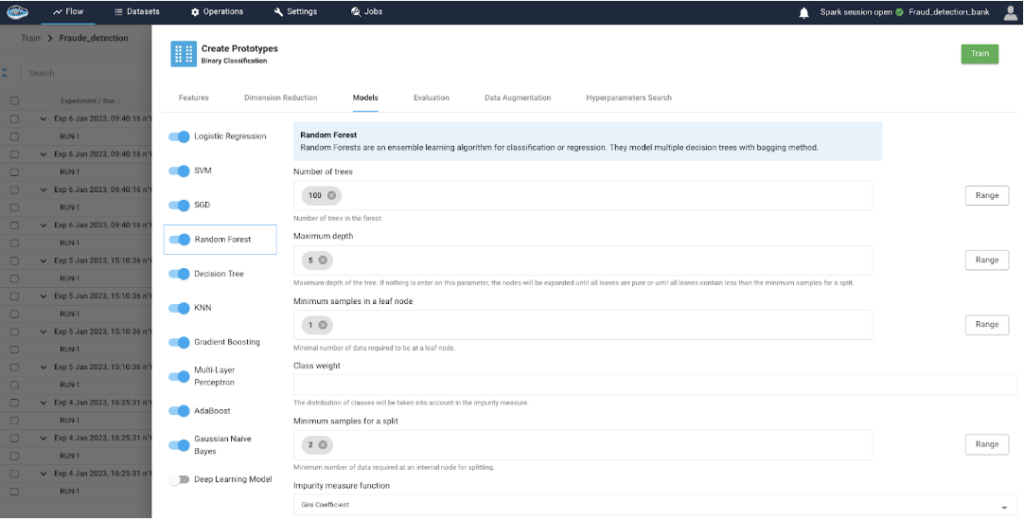
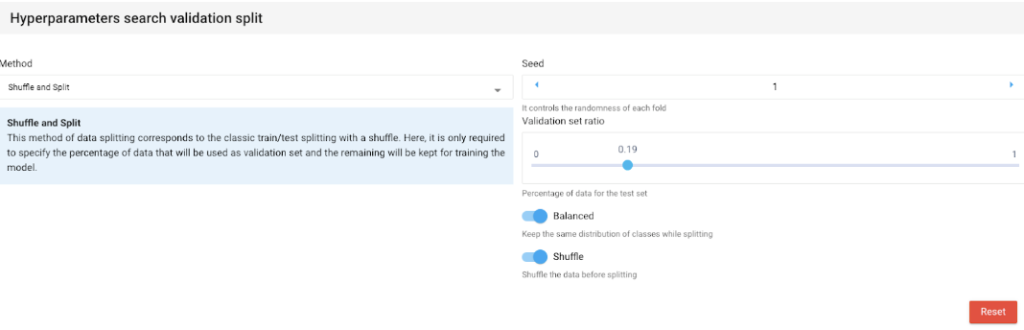
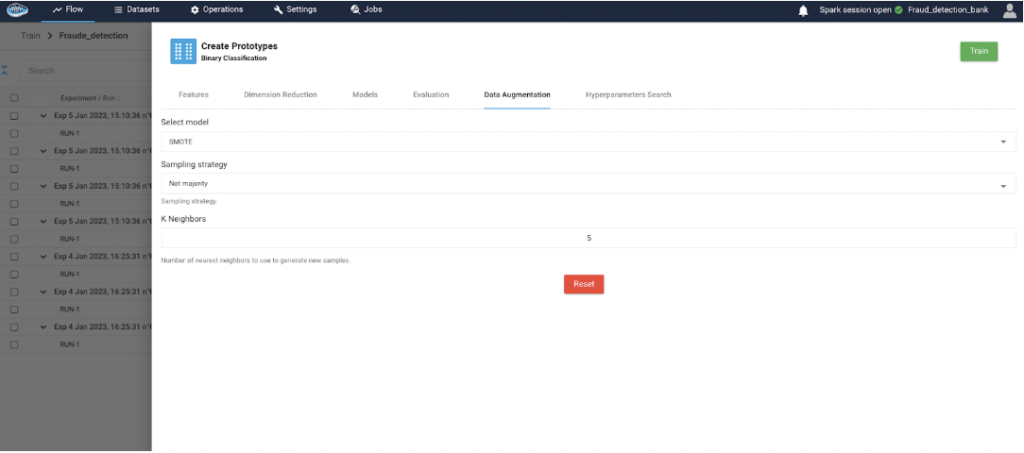
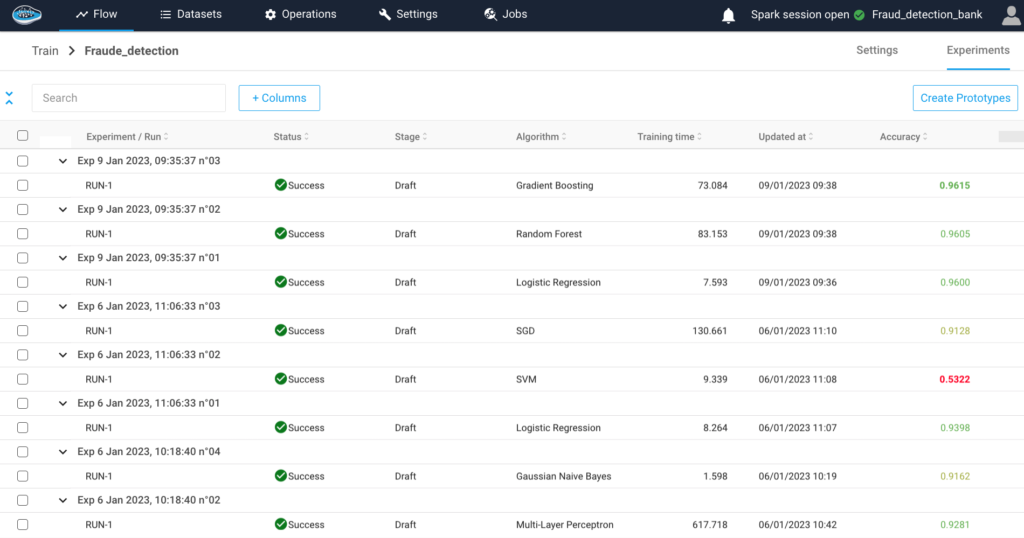
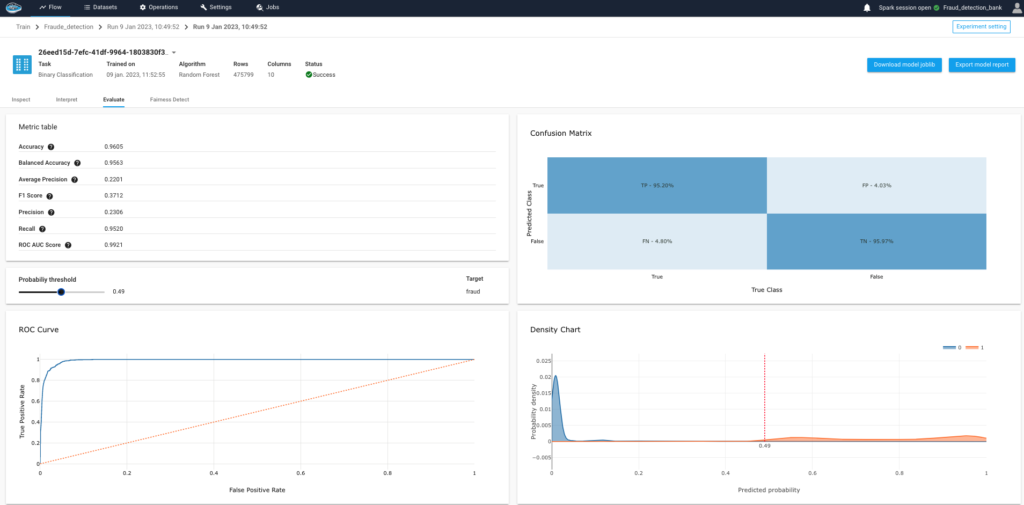
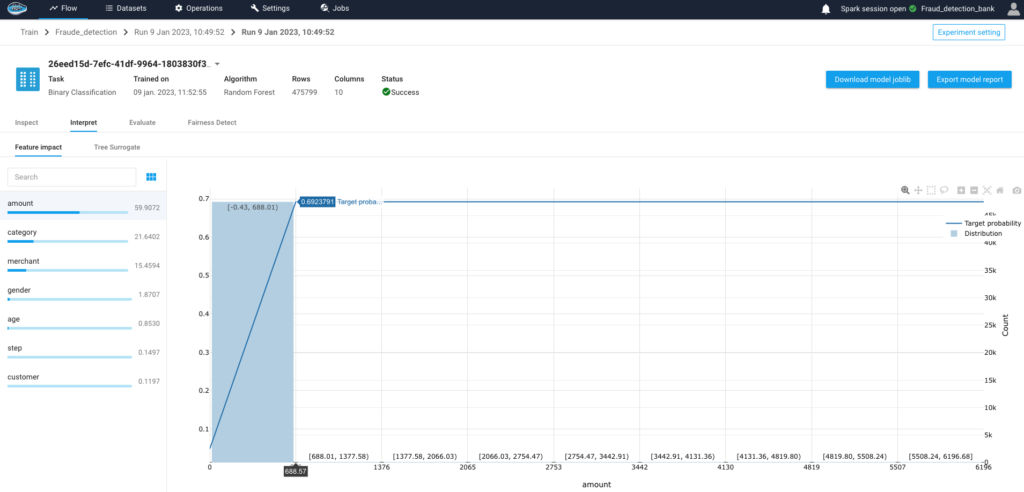
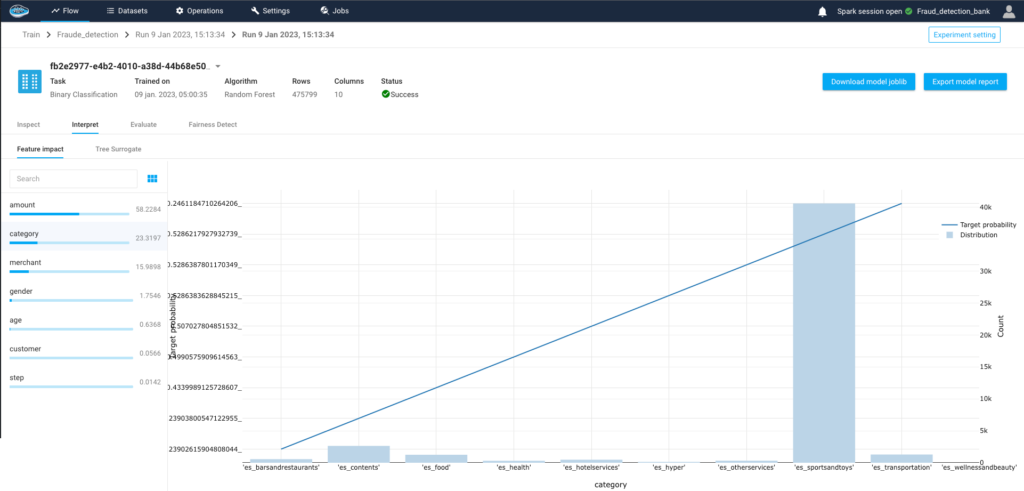
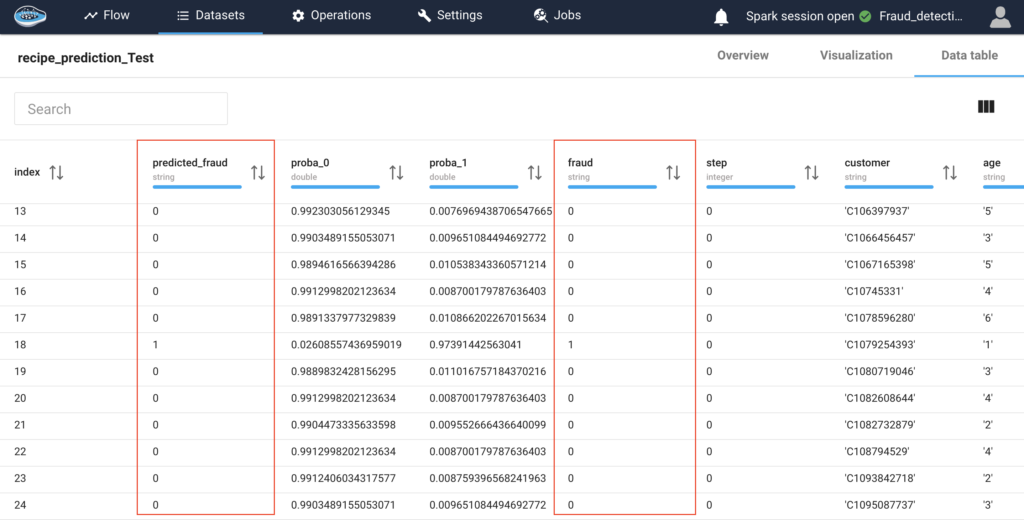
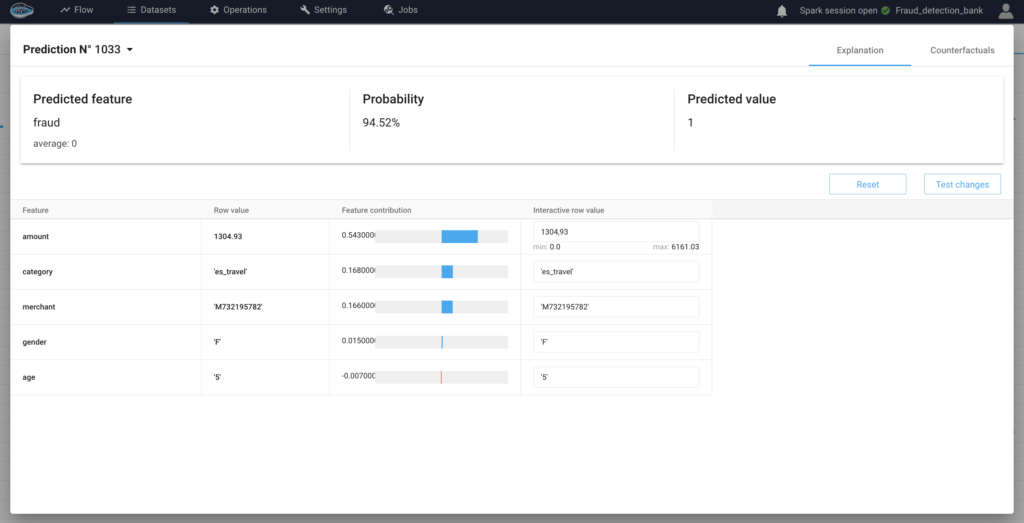

How AI Transforms Predictive Maintenance in Defense Equipment
How AI Transforms Predictive Maintenance in Defense Equipment In a...
Read More
How to Scale AI Without Breaking Your Infrastructure in 2025
How to Scale AI Without Breaking Your Infrastructure in 2025...
Read MoreHow is papAI transforming fraud detection in Banks ?