
Why Should You Consolidate Your AI Tools for Faster Scaling?...
Read MorePowerful Named Entity Recognition on papAI
Table of Contents
ToggleThe new version of papAI7.4 brings a major enhancement to its Natural Language Processing capabilities with the introduction of Named Entity Recognition (NER). This powerful module is designed to automatically detect and categorize key entities within text, such as people, places, organizations, dates, and numerical values. By transforming unstructured information into actionable insights, NER significantly boosts the analytical power of papAI7.4 across a wide range of use cases.

We’ll define NER’s function and its vast possibilities across various industries within this article.
What is Named Entity Recognition (NER)?
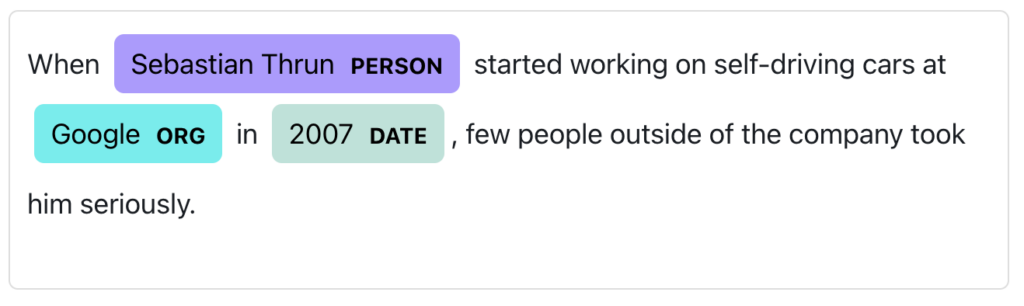
Named Entity Recognition, or NER for short, is a natural language processing (NLP) method that focuses on identifying and categorising certain information in a textual corpus. People, places, organisations, dates, monetary values, and more can all be included in these “entities”—pieces. The objective is to identify the kind of information that these essential components represent. A competent NER system would identify “Apple” as an organisation and “Paris” as a location in the sentence “Apple opened a new store in Paris,” for instance.
The capacity of NER to transform unstructured text into structured data is what makes it so useful. Consider customer reviews, news articles, social media posts, or legal documents as examples of real-world applications where businesses must extract valuable information from large volumes of text. NER makes data analysis, content summarization, and trend discovery easier by automatically classifying and identifying these things. It is a powerful backend system that supports chatbots and search engines alike.
How is NER feature implemented on papAI?
The Named Entity Recognition (NER) function in papAI7.4 is implemented using a strong base of established natural language processing (NLP) technology. One of the most reputable and powerful natural language processing libraries on the market today, spaCy, is the foundation of this module. We can provide fast, reliable, and extremely accurate entity recognition at scale because to SpaCy’s adaptable and effective framework. We’ve gone one step farther than simply incorporating spaCy, though, by creating a layered and modular architecture that guarantees flexibility and future-proofing, making the NER module both resilient and expandable.
Tok2Vec layer
The Tok2Vec layer, the first essential part of this architecture, is essential to the system’s ability to “understand” language. Each word in a sentence is transformed into a dense vector representation, which functions as a kind of mathematical fingerprint that encapsulates the meaning of the word depending on its context and usage.
This enables the model to understand linguistic nuances, like differentiating between the term “Apple” as a fruit and “Apple” as a business. Tok2Vec enables dynamic understanding by modifying word interpretations in response to surrounding material, in contrast to conventional approaches that depend on fixed word meanings. Accurate NER requires this context awareness, especially when working with ambiguous or domain-specific terminology.
NER Layer
The second crucial element, the NER Layer, receives the data after the text has been converted into these context-rich vectors. The real power of entity recognition takes place here. As it goes through the vectorized input, the NER layer assigns a particular entity label, such as PERSON, ORG (organisation), GPE (geopolitical entity), DATE, or MONEY, among others, to each pertinent textual segment.
This method involves more than just identifying proper nouns; it also entails comprehending the sentence’s structure and meaning sufficiently to extract the appropriate pieces. For example, the model accurately recognises “Tesla” as an organisation and “January” as a date in a sentence such as “Tesla’s stock surged in January,” guaranteeing accurate and practical results.
papAI NER Workflow: A Step-by-Step Tutorial
1. Raw Text Starting point:
A document written in natural language (sentence, paragraph, etc.). Example: “Emmanuel Macron is the President of the French Republic.”
2. Tokenization:
The tokenizer splits the text into tokens based on precise linguistic rules that depend on the language used (handling punctuation, spaces, contractions, etc.). Result: [Emmanuel, Macron, is, the, President, of, the, French, Republic, .]
3. Tok2Vec (Embedding + Contextual Encoding):
The Tok2Vec module transforms each token into a dense contextual vector through two configurable subcomponents:
a) Embedding (embed)
Each token is converted into a vector based on its surface features using:
- MultiHashEmbed: Multiple hashing on sub-units of text (prefixes, suffixes, etc.).
- CharacterEmbed: Character-based representation (useful for handling rare or unknown words).
b)Encoder (encode) :
The embedding vectors are then contextualized (taking into account the surrounding lexical context) using an encoder:
- MaxoutWindowEncoder or MishWindowEncoder: Non-recurrent sliding window encoders.
- TorchBiLSTMEncoder: Bi-directional LSTM-based encoder (deeper, richer in context).
Output of Tok2Vec: Each token is now represented by a rich contextual vector, ready to be used by the prediction layers.
4. NER (Named Entity Recognition):
This layer predicts a named entity label for each token. It learns to detect entities (people, places, dates, etc.) based on the vectors provided by Tok2Vec.
4-bis. Relation Extractor
This layer takes the detected entities and examines all relevant pairs.
It uses:
- The vector representations (span vectors) of entities, provided by Tok2Vec.
- The local context between entities.
- A small neural network (MLP) to predict whether a specific relationship exists between two entities.
5. Structured Output:
The text is enriched with:
- Identified and classified entities.
- Explicit relationships between these entities.
This data can be integrated into databases, dashboards, or business analytics systems.
What are the Benefits of using NER on papAI?
UX-Friendly Experience
One of the strongest advantages of using the Named Entity Recognition (NER) module on papAI is how seamlessly it’s designed for users of all skill levels. Unlike many machine learning tools that require complex coding and scripting, papAI provides an intuitive, user-centric interface that makes it easy to launch NER tasks directly from the platform. Whether you’re a data scientist, a domain expert, or a business analyst with no programming background, you can start extracting meaningful entities from your text data within minutes.
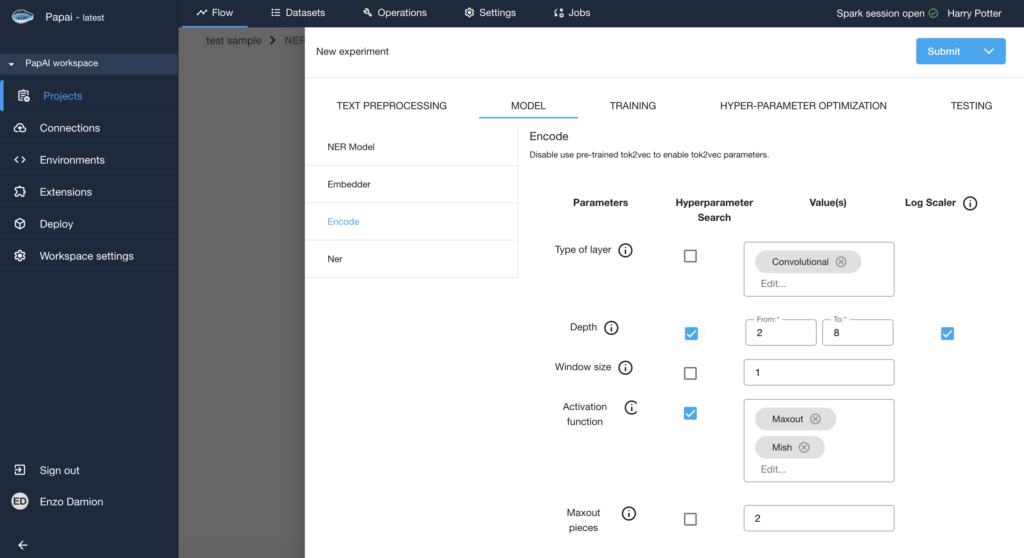
Parametrization of the encoding layer of the model using hyper-parameter search.
Pre-trained Models (only for NER)
papAI’s NER module is built with practicality and performance in mind, and that starts with its seamless integration of SpaCy’s pre-trained models—widely respected in the NLP community for their robustness and reliability. These models let you hit the ground running without the usual overhead of data preparation or manual labeling.
For every supported language, papAI offers three different model sizes—small, medium, and large—each optimized for a trade-off between speed and accuracy. In total, the platform supports 72 pre-trained models across 24 languages, making it one of the most versatile tools for multilingual entity extraction on the market. Whether you’re analyzing English business reports, French legal contracts, or German news articles, papAI has a model ready to deploy.
The number of entity types (or “labels”) that these models can recognize depends on the language. For example, English comes packed with over 18 entity types, including:
PERSON (e.g., “Emmanuel Macron”)
ORG (e.g., “European Union”)
GPE (countries, cities, regions)
LAW, DATE, MONEY, PRODUCT, and more.
French, while having fewer pre-trained labels—PER, ORG, LOC, and MISC—is still perfectly suited for common use cases in administration, news, and business documents.
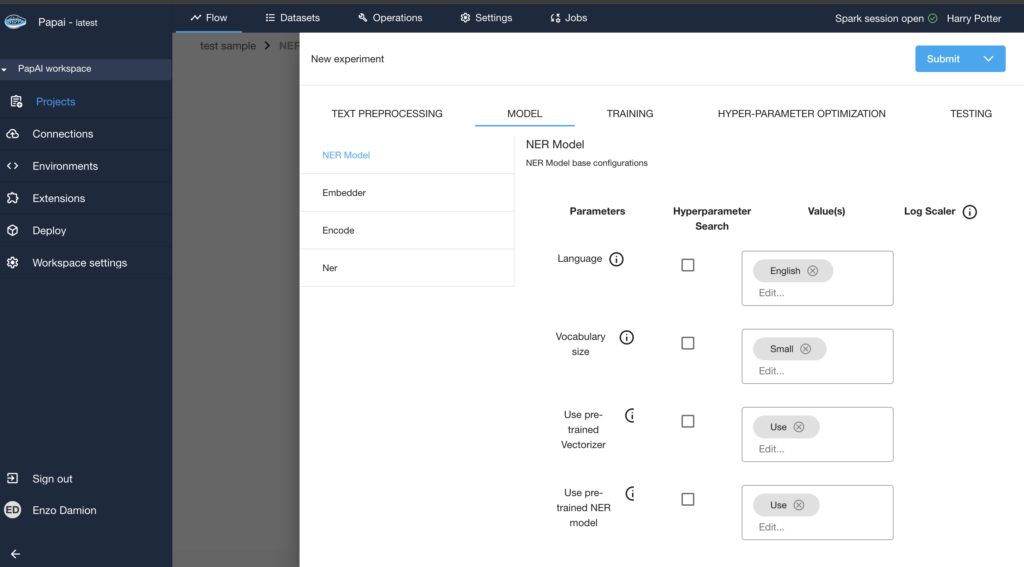
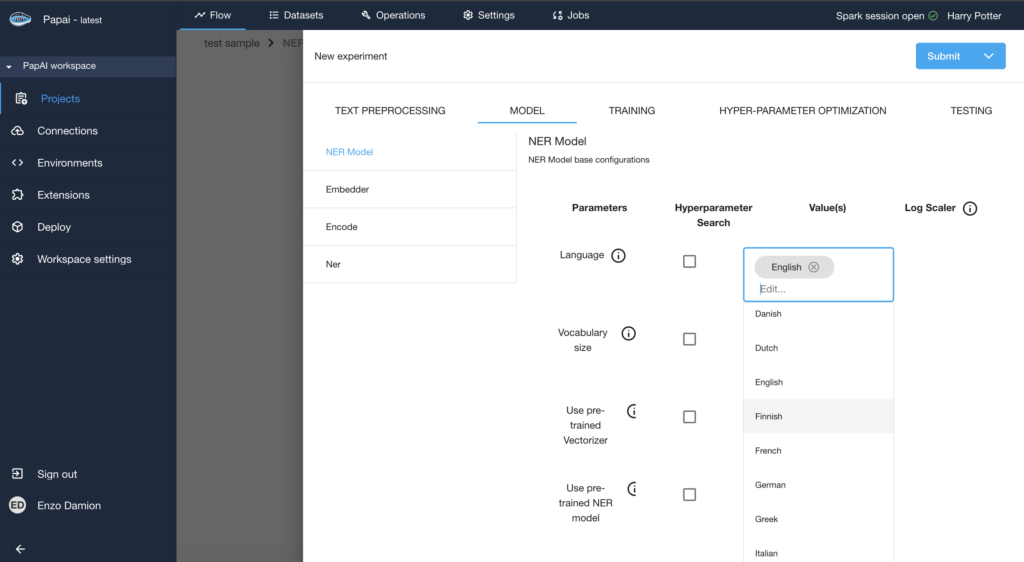
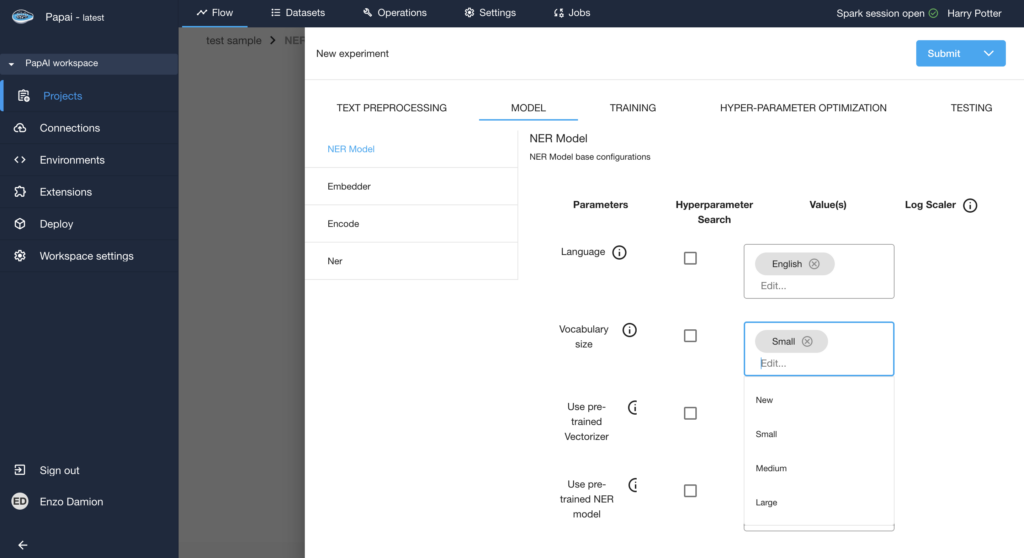
Selection of the (Language/Size) & Model Configuration
Train your model from scratch
You can either adapt a pre-trained SpaCy model to your needs or build a brand-new NER model from scratch. This is ideal when your data includes specialized vocabulary, such as biomedical terminology, legal clauses, or product identifiers that go beyond general-purpose labels.
What makes this process even more accessible is papAI’s visual, no-code environment, which walks you through every step: from uploading training data, setting label definitions, choosing encoder types (like BiLSTM or Transformer), to adjusting learning rates and evaluation parameters. Even users without a machine learning background can confidently build and deploy high-performing custom models tailored to their use case.
All of SpaCy’s potent features are accessible through papAI, which also provides a guided experience that guarantees best practices are followed without being overbearing to consumers. It is the ideal balance of usability and power.

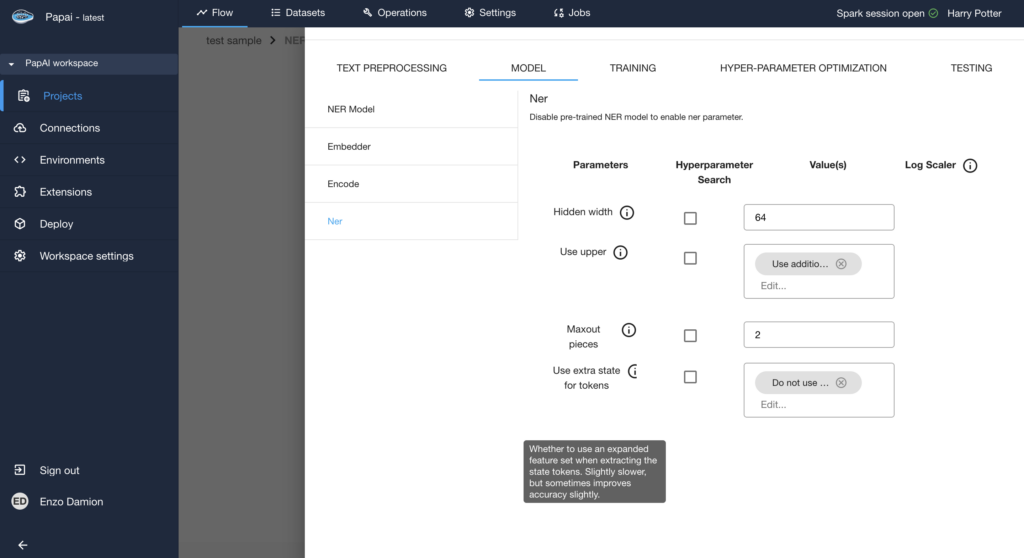

Parametrization of the embedding & encoding layer of the model
What are the Real-World Applications of NER?
HR: Automatically extract names, qualifications, dates and experience from CVs received
Context:
Every week, dozens or even hundreds of resumes are sent to HR departments. Although in unstructured formats, each document includes essential information such as candidate names, degrees, talents, job titles, and dates of employment. The layout, wording, and style of these resumes differ, which makes manual analysis laborious and unreliable. Recruiters invest hours in data extraction and screening, a process that is subject to bias and human error. HR departments require more intelligent solutions to manage this amount of data effectively in a time when accuracy and speed are essential for hiring new employees.
Use Case:
papAI’s NER module can transform this manual CV screening process into a streamlined, automated pipeline. The system reads each incoming CV—whether in PDF, DOCX, or plain text—and extracts predefined entities such as names, degrees, certifications, skills, employment dates, job titles, and even previous employers. For example, from the sentence “Jane Smith earned a Master’s in HR from Sorbonne and worked at Airbus from 2020 to 2023,” papAI will identify “Jane Smith” as a PERSON, “Master’s in HR” as a QUALIFICATION, and “2020 to 2023” as a DATE range. It does this in multiple languages and with high precision, thanks to SpaCy-based NER models under the hood.
Benefits from papAI:
HR managers can save hours each week and concentrate on activities that need a human touch, such as candidate engagement or interviews, by automating entity extraction. Fast filtering and comparison are made possible by the structured data generated from papAI, which also enhances fairness by lowering subjective errors and seamlessly integrates into ATS or HR dashboards. Additionally, papAI’s no-code environment allows HR departments to refine models to identify roles or specialised skills unique to a company, making it a strong and customised solution.
Insurance: identify the names of insured parties, accident locations, and reimbursement amounts in claims
Context:
Processing claims in the insurance industry involves handling a significant amount of semi-structured or free-text data, including digital forms, handwritten reports, scanned PDFs, and emails. Important details, including the insured person’s identity, the accident scene, the date of the incident, and the requested reimbursement amount, are all included in every claim file. In addition to being laborious and slow, manually extracting these data pieces exposes businesses to mistakes, delays, and regulatory issues. Insurers are facing pressure to digitise and streamline their back-office processes as customer expectations for speedy service increase.
Use Case:
Insurers can automate the process of extracting essential components from claim paperwork by using papAI’s NER module. PapAI recognises “Eric Billard” as a PERSON, “Marseille” as a LOCATION, “12 April 2023” as a DATE, and “€2,500” as a MONEY amount when processing a claim report such as “Eric Billard reported an accident in Marseille on 12 April 2023 and requested €2,500 in reimbursement.” SpaCy-powered NER models enhanced with contextual awareness are used to accomplish this instantaneously across documents, irrespective of their format or complexity. Even in complex legal documents or multilingual instances, papAI does more than simply highlight words; it also interprets them contextually to guarantee accurate classification.
Benefits from papAI:
Insurance teams may improve accuracy, guarantee compliance, and shorten claim processing times by automating entity recognition. Internal systems can automatically filter, route, and prioritise claims with structured output, speeding up workflows and reducing the possibility of human error. Additionally, teams may refine the models using industry-specific keywords like policy numbers or coverage codes because to papAI’s no-code interface. This enables insurers to increase operational efficiency, transparency, and customer happiness while expediting reimbursements, all without requiring sophisticated technical expertise in-house.
Legal: identifying the names of individuals, companies, and laws mentioned in a contract
Context:
Contracts, agreements, and regulatory papers that include crucial information buried in lengthy paragraphs of complex legalese are frequently dealt with by legal teams. A time-consuming but crucial aspect of legal review is determining the names of the parties involved, the businesses mentioned, and the precise laws or rules mentioned. This job is typically completed by hand, line by line, phrase by phrase. This method is laborious and prone to error, particularly when deadlines are short. Even minor mistakes might have major legal or financial repercussions in a field where accuracy is crucial.
Use Case:
By automatically extracting important legal entities from contracts, papAI’s NER module streamlines and expedites the examination of legal documents. For example, papAI will identify “Article L.225-129 of the French Commercial Code” as a LAW, “Vinci SA” as an ORGANISATION, and “Mr. Paul Durand” as a PERSON from a sentence such as “According to Article L.225-129 of the French Commercial Code, the company Vinci SA must notify Mr. Paul Durand.” Even in multi-page agreements and cross-jurisdictional documents, it functions well. PapAI’s robust pre-trained models and adaptable training options enable it to recognise the unique legal terminology used by various businesses or sectors.
Benefits from papAI:
When it comes to contract analysis and due diligence, papAI’s NER offers legal practitioners a new degree of speed and consistency. The software helps teams traverse complex documents more quickly and lowers the chance of missing important phrases or parties by automatically identifying names, businesses, and legal references. For further analysis or automation, the retrieved data can be entered into contract lifecycle tools, legal databases, or compliance systems. Additionally, legal teams can refine the model to recognise regional legal codes or internal language owing to papAI’s user-friendly, no-code interface, freeing up specialists to concentrate on strategic legal reasoning rather than tedious data entry.
Marketing: analyse customer comments to identify the brands or products mentioned
Context:
Consumers in the digital age frequently express their thoughts online through blog postings, social media, product evaluations, and feedback questionnaires. This user-generated content is a treasure trove of information for marketing teams. The difficulty, however, is effectively sorting through hundreds of comments to find out what people are saying about particular companies, goods, or attributes. It is slow and unpredictable to manually analyse this unstructured data, and traditional keyword searches frequently overlook subtleties or brand variants. This is when more intelligent tools like NER are useful.
Use Case:
papAI’s NER module allows marketing teams to automatically scan customer comments and identify all references to brand names, product lines, and even competitive mentions. For example, from the sentence “I switched from Samsung to the new iPhone 15 and I love the camera,” papAI recognizes “Samsung” and “iPhone 15” as PRODUCT entities. Whether it’s detecting recurring praise for a specific feature or spotting early signs of dissatisfaction, papAI helps convert raw feedback into structured insights. Thanks to SpaCy’s pre-trained models and multilingual support, the system works across languages and platforms—be it reviews on Amazon, tweets, or internal surveys.
Benefits from papAI:
Marketing teams are no longer forced to rely on assumptions or insufficient analysis thanks to NER’s integration with papAI. The tool provides a clear map of what consumers are discussing, which brands are receiving attention, and how consumers view certain products. This makes it possible to make data-driven decisions more quickly, whether they are about starting a campaign, improving a message, or modifying product strategy. Furthermore, it is simple to modify the model to learn specialised product names, industry-specific terminology, or even slang because of papAI’s no-code environment. As a result, you can gain a deeper insight into your industry in real time without requiring a degree in data science.

“NER is where AI moves from theory to impact, turning everyday text into actionable insights. With papAI, we’ve made this power accessible to every team.”
Thibaud ISHACIAN
Head of Product - Datategy
Train Your Own NER and Take Control of Your Data with papAI
One of the most noticeable and significant uses of AI in actual business operations is Named Entity Recognition (NER). Teams can now automatically recognise and categorise important information from unstructured text, such as names, dates, locations, organizations, or product mentions, saving hours of human labour and lowering errors, thanks to the release of papAI 7.4.
The NER module from papAI revolutionizes the way you manage documents, derive insights, and make choices, regardless of your industry. with its user-friendly, no-code interface and SpaCy-powered architecture, papAI provides both pre-trained and customisable models for complete versatility. Book your Demo now.
Interested in discovering papAI?
Our AI expert team is at your disposal for any questions

Why is Deployment Speed the New 2026 AI Moat?
Why is Deployment Speed the New 2026 AI Moat? The...
Read More
We Don’t Just Build AI, We Deliver Measurable Impact
We Don’t Just Build AI, We Deliver Measurable Impact Join...
Read More
AI’s Role in Translating Complex Defence Documentation
AI’s Role in Translating Complex Defence Documentation The defence sector...
Read MorePowerful Named Entity Recognition on papAI
Summary

Article Name
Powerful Named Entity Recognition on papAI
DescriptionDiscover Named Entity Recognition (NER) on papAI7. Automatically extract key information like names, places, and organizations from your text data.
Author
Hocine ousmer
Publisher Name
Datategy
Publisher Logo