
How AI-Powered Anti-Drone Solutions Transform Defense Operations? Drones are everywhere...
Read More

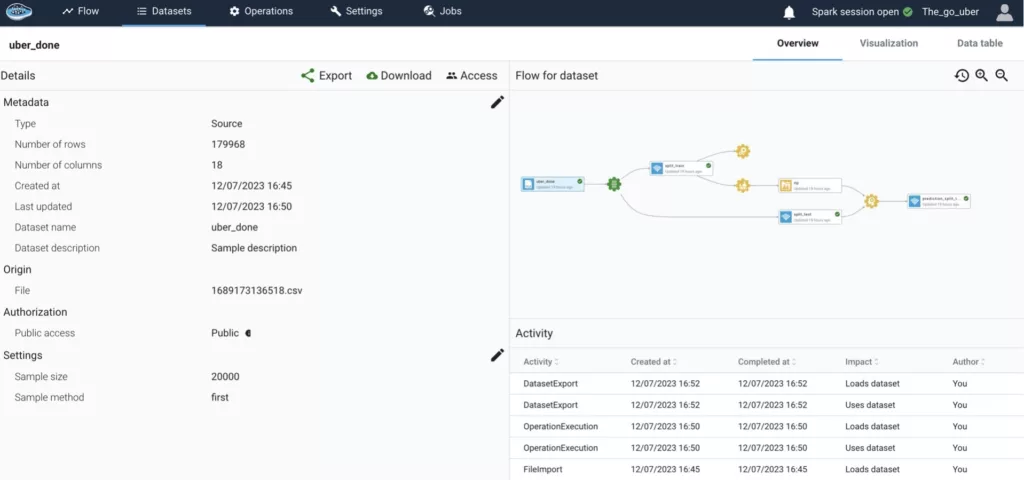
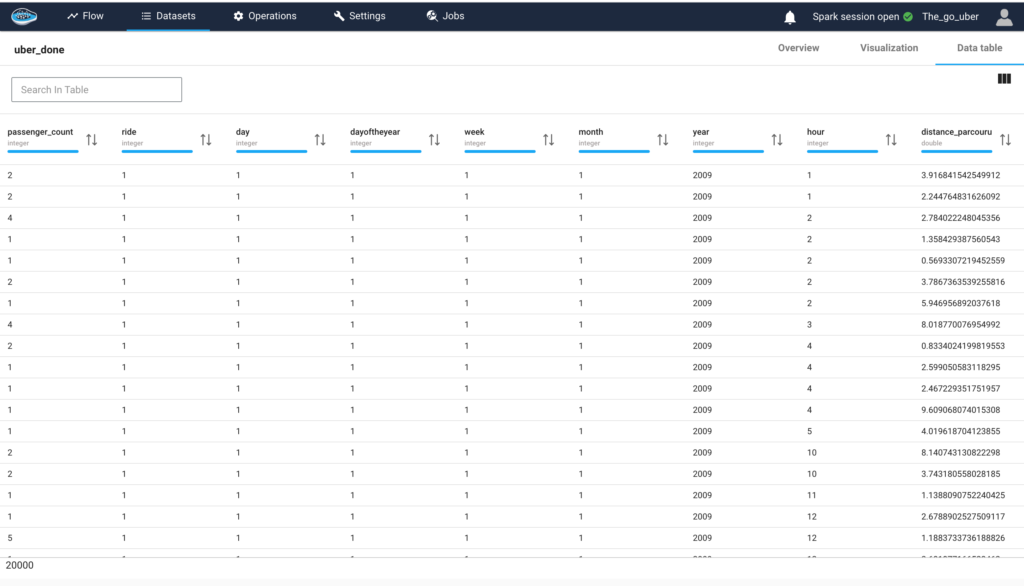
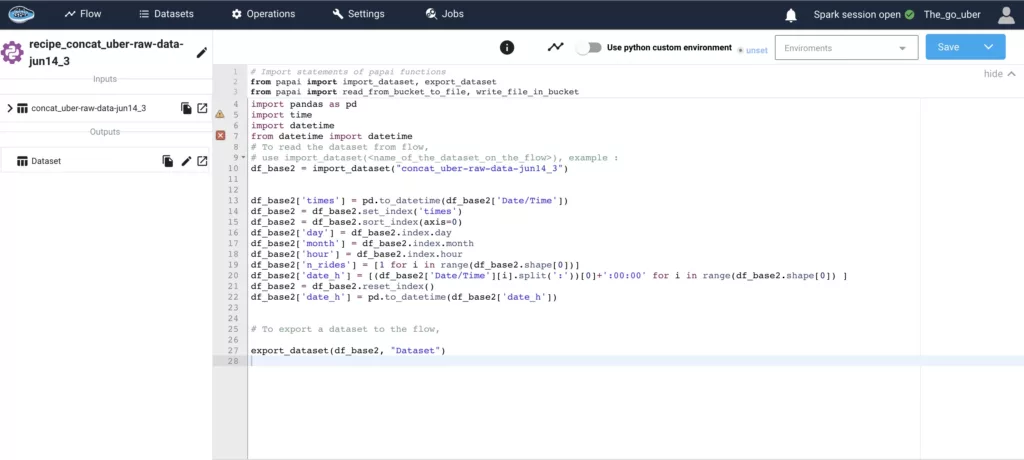
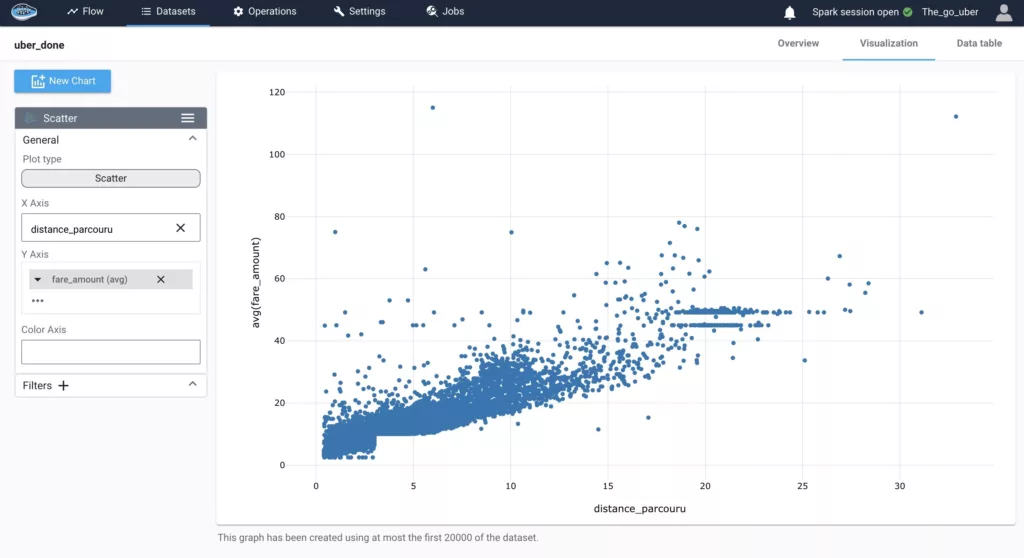

Transform Defense Logs & Rapport into Situational Awareness with AI
Transform Defense Logs & Rapport into Situational Awareness with AI...
Read More
Why AIOps Is Key to Cyber Threat Detection in Defense?
Why AIOps Is Key to Cyber Threat Detection in Defense?...
Read More
How AI Transforms Predictive Maintenance in Defense Equipment
How AI Transforms Predictive Maintenance in Defense Equipment In a...
Read MoreNext-Gen Urban Ride Platforms: Forecasting Demand & Costs using papAI