
Why Should You Consolidate Your AI Tools for Faster Scaling?...
Read MoreApplying NLP for Intelligent Document Analysis
using papAI 7
Table of Contents
ToggleAI technologies have emerged as a disruptive tool in a large number of fields, one of the most useful being Natural Language Processing (NLP).
In this field, its ability to analyze large quantities of text is a major asset when analyzing documents of all types (articles, press releases, financial reports, etc.).
80% of all enterprise data is unstructured. NLP is a perfect fit for digital transformation projects as it helps derive insights from unstructured data.
Find out how papAI can improve the deployment of AI projects in Sales & Marketing.

In this article, we will define NLP approaches and how they can help improve document analysis.
What does Natural Language Processing (NLP) Mean?
The branch of artificial intelligence known as “natural language processing” (NLP) is concerned with how computers and human language interact. NLP essentially makes it possible for computers to comprehend, interpret, and produce meaningful, contextually relevant human language.
This multidisciplinary area uses techniques from computer science, artificial intelligence, and linguistics to create models and algorithms that can handle and analyze massive amounts of natural language data.
Fundamentally, NLP aims to enable machines to interpret and react to human language inputs, therefore bridging the gap between human communication and computer comprehension. Text categorization, sentiment analysis, machine translation, and speech recognition are just a few of the many jobs involved in this.
NLP algorithms may extract useful insights from textual data by utilizing machine learning and deep learning techniques. This allows applications like chatbots, virtual assistants, and language translation services to connect with users more efficiently.
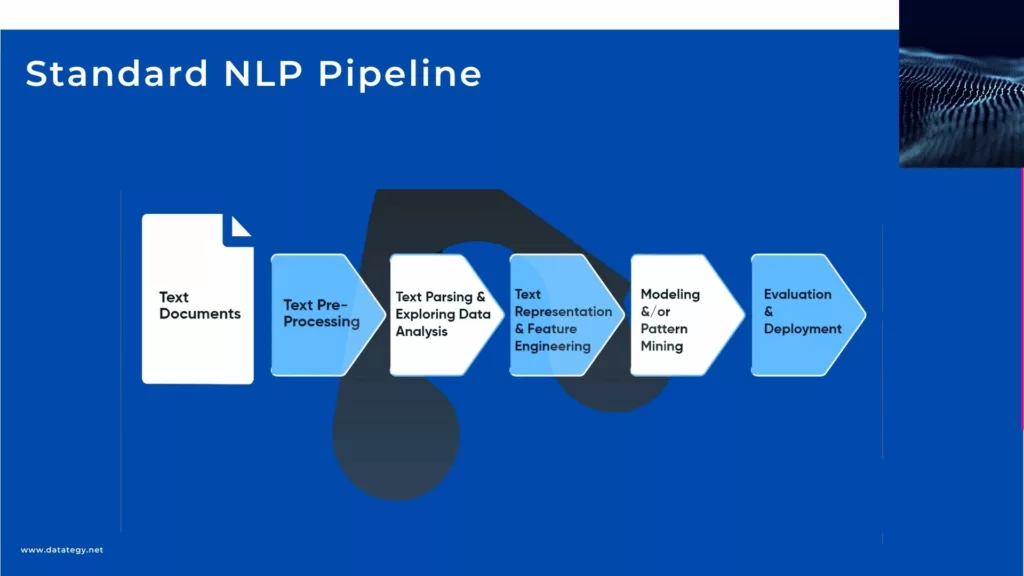
Standard NLP Pipeline
The different NLP techniques
Tokenization
Tokenization is a basic natural language processing (NLP) approach that entails segmenting text into smaller pieces called tokens, which can be words, phrases, or sentences. Text may be more easily analyzed and processed by using tokenization, which divides text into these discrete components. Consider the following line, for instance: “The quick brown fox jumps over the lazy dog.” If this sentence were tokenized, it would look like this: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “.”]. A unique textual element is represented by each token, enabling additional manipulation and analysis.
Stemming
Reducing words to their stems—basic or root forms—is a technique called stemming. This method works especially well for normalizing word variants, such as plurals or distinct verb tenses, to increase the accuracy of analysis. The terms “running”, “runs”, and “ran” are derived from the same root form, “run”. Even if stemming doesn’t always yield a term that makes sense, it makes text analysis jobs easier to complete and helps capture the meaning of words.
Lemmatization
Lemmatization is a process that seeks to reduce words to their canonical or dictionary form, sometimes referred to as a lemma. It is related to stemming. Lemmatization takes the word’s context into account and guarantees that the generated lemma is a legitimate term, in contrast to stemming. The terms “am,” “are,” and “is,” for instance, would all lemmatize to the basic form “be.” By guaranteeing that words are converted into their correct dictionary form, lemmatization ensures that semantic meaning is maintained and increases the accuracy of text analysis activities.
Sentiment analysis
The technique of identifying the emotional tone or sentiment contained in text data is commonly referred to as opinion mining or sentiment analysis. Customers’ reviews, social media posts, product evaluations, and other textual data are frequently analyzed using this method to determine how the general public feels about a certain subject or thing. Sentiment analysis is a tool that helps businesses understand consumer opinions, spot patterns, and make data-driven choices by classifying text as positive, negative, or neutral.
Text Classification
Text classification or categorization is the process of grouping text materials according to their topics or substance into pre-established classes or categories. This method is frequently applied in many different fields, such as document organization, sentiment analysis, subject classification, and spam detection. In order to classify fresh text documents into relevant categories, text classification algorithms are trained using labeled training data. For instance, depending on their content and other features, incoming emails may be categorized as spam or not by an email spam filter.
Demystifying AI: A Comprehensive Guide to Key Concepts and Terminology
This guide will cover the essential terminology that every beginner needs to know. Whether you are a student, a business owner, or simply someone who is interested in AI, this guide will provide you with a solid foundation in AI terminology to help you better understand this exciting field.

What are the Advanced Approaches and Models in NLP?
Deep Learning Models for Document Understanding
More complex and precise document interpretation is now possible due to deep learning, which has completely changed how computers analyse and interpret documents. Unstructured and semi-structured texts are frequently difficult for traditional rule-based or statistical approaches to handle, however deep learning models may manage these difficulties by using big datasets and identifying complicated patterns.
Deep learning’s capacity to extract context-rich information without the need for manual feature engineering is one of its main advantages in document analysis. In order to analyze sequential input, such as text, recurrent neural networks (RNNs) and long short-term memory (LSTM) networks have been employed extensively. This enables models to preserve context between phrases. Transformer-based designs have become more popular as a result of these models’ shortcomings while handling lengthy texts, which greatly increase processing performance and context preservation.
Architectures Based on Transformers
Since transformers are effective and can capture long-range relationships in text, they have emerged as the foundation of contemporary natural language processing. Transformers process complete texts in parallel using self-attention processes, which greatly increases speed and accuracy compared to previous deep learning models that depended on sequential processing.
One of the earliest transformer models, BERT (Bidirectional Encoder Representations from Transformers), revolutionized document comprehension. Compared to earlier models, it is better at capturing context dependencies and subtle meanings since it reads text in both directions. More robust document categorization, summarization, and extraction result from extensions like RoBERTa, XLNet, and T5.
Models Based on Graphs
A distinct method of document analysis is offered by graph-based models, which depict text and structural components as nodes in a graph with edges reflecting the interactions between them. For complicated document structures like contracts, research papers, and legal documents, graph neural networks (GNNs) are perfect because they can capture non-linear interactions inside a document, unlike typical deep learning models that concentrate on sequential input.
In practical applications, graph-based methods are employed in scientific literature analysis, fraud detection, and legal document examination to assist glean insights beyond basic keyword matching. In order to comprehend links both inside and between documents, graph-based models will become more and more crucial as document processing grows more complex.
Neural Networks (CNNs)
Convolutional neural networks, or CNNs, are extensively employed in computer vision and have shown great promise in document layout analysis. Because text, photos, tables, and other visual components are frequently mixed together in documents, CNNs use spatial hierarchies to assist detect and categorize these items.
CNNs are used in document processing to separate various parts including tables and headers, identify text sections, and categorize document structures. They are excellent at identifying patterns in scanned documents, which makes it possible to automate the digitization and extraction of structured data.CNNs’ resilience in processing noisy or degraded documents is one of its main advantages. By concentrating on document layout and guaranteeing that extracted information maintains its structure and meaning, they improve text recognition when used in conjunction with OCR. In financial papers, plans, and newspaper archives, where layout is crucial to comprehending text, CNNs are very useful.
What are the Advantages of NLP in Document Analysis?
- Enhanced Efficiency: By automating the process of obtaining insights from massive volumes of text documents, natural language processing (NLP) greatly increases the efficiency of document analysis. Text data analysis done by hand may be labour- and time-intensive, including a lot of human reading, interpreting, and categorization work.
As opposed to this, natural language processing (NLP) algorithms are able to handle text data on a large scale, analyzing hundreds or even millions of documents in a fraction of the time that a human analyst would need. NLP expedites the document analysis process by automating repetitive operations like data extraction, classification, and summarising. This enables businesses to analyze text data more effectively and devote human resources to more important work.
- Higher Accuracy: NLP algorithms use sophisticated linguistic and statistical methods to accurately extract meaningful information from text input. NLP systems may identify important entities, themes, and sentiments inside texts by using techniques like named entity recognition (NER), sentiment analysis, and topic modeling.
This allows for more precise analysis and decision-making. For instance, sentiment analysis algorithms can reliably identify the text’s emotional tone and categorize it as positive, negative, or neutral. This enables businesses to more precisely assess the mood or opinion of their clientele.
- Multilingual Support: Natural language processing (NLP) techniques are appropriate for businesses that operate in linguistically varied contexts because they can analyze text material in different languages. NLP facilitates worldwide operations and decision-making by enabling organizations to extract insights from text data in several languages through multilingual document analysis.
For instance, multilingual sentiment analysis algorithms are able to precisely identify the sentiment or opinion of a text in a variety of languages, giving businesses the ability to assess client sentiment across several marketplaces. NLP enables businesses to analyze text data from a variety of sources and languages, giving them the ability to obtain insights and make well-informed choices on a worldwide basis. This is accomplished by offering multilingual assistance.
- Compliance and Risk Management: By automatically searching documents for pertinent information, natural language processing (NLP) may assist organizations in managing risks and ensuring compliance with rules. Through the identification of compliance concerns, regulatory infractions, or possible dangers included in text documents, natural language processing (NLP) tools empower organizations to promptly undertake risk mitigation and regulatory compliance measures.
Compliance monitoring algorithms have the capability to automatically search text documents for references to regulatory requirements or sensitive themes. This enables organizations to promptly detect and resolve compliance concerns. NLP helps businesses lower the risk of non-compliance and make sure they follow regulations by offering automated compliance monitoring and risk management tools.
What Challenges do Companies Face When it Comes to NLP?
Businesses that use Natural Language Processing (NLP) technology face a number of obstacles. First, there are a lot of obstacles related to data quantity and quality.
NLP models require vast amounts of high-quality data for effective training, yet enterprises often grapple with unstructured and disparate data sources. It becomes crucial to ensure data relevance, cleanliness, and consistency in order to reduce biases and raise model accuracy. Furthermore, handling several languages and dialects is a challenge for NLP systems to serve international markets due to the complexity of multilingual data.
Second, there are issues with NLP models’ interpretability and explainability, especially in sectors with strict regulatory requirements. To abide by rules and uphold confidence, businesses must guarantee that the decision-making process used by NLP models is transparent.
It becomes essential to strike a balance between interpretability and model complexity since too complicated models might provide results that are opaque to stakeholders and make them difficult to comprehend and accept.
It’s also worth noting that more than three-quarters of organizations expect to spend more on NLP projects in the next 12-18 months. This indicates a growing recognition of the value of NLP, despite the challenges.
Advanced NLP Applications: How is papAI 7 used in Intelligent Document Analysis?
Overview of papAI 7
papAI 7 is an advanced end-to-end AI platform designed to revolutionize the way organizations harness the power of artificial intelligence. With its comprehensive suite of features and capabilities, papAI 7 empowers users to streamline their AI development process from data preprocessing to model deployment. This platform offers a wide range of tools and functionalities to support various AI tasks, including data preprocessing, feature engineering, model training, evaluation, and deployment.
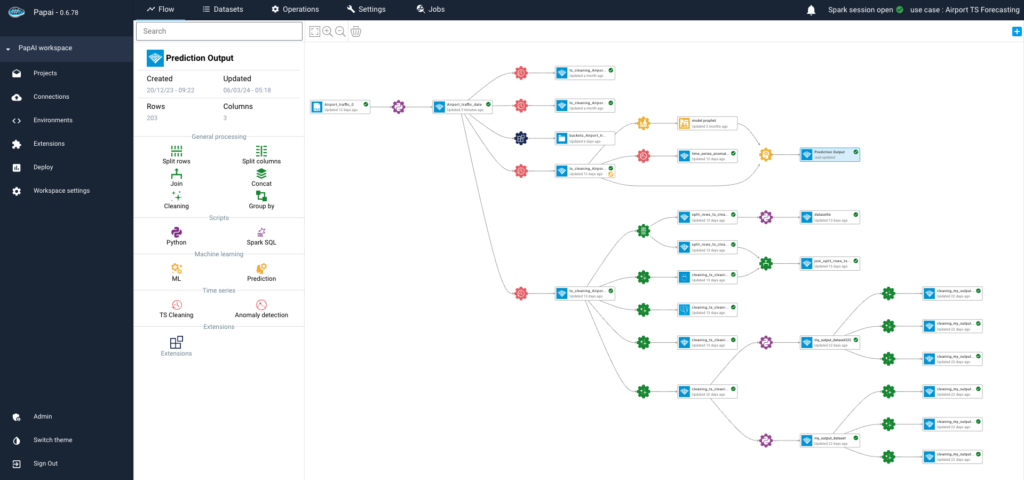
papAI 7 Workflow
Financial Document Entity Detection using NLP : A Comprehensive Guide
Identifying and extracting crucial data from financial documents requires the use of cutting-edge technology like machine learning and natural language processing (NLP) to identify certain entities and phrases. Terms might include acronyms, industry-specific jargon, rules, and KPIs, while entities could include names of businesses, people, dates, financial numbers, and more.
This use case is essential to the financial industry’s process simplification efforts because it allows stakeholders to obtain insightful information from a variety of financial data sources.
The precise extraction of entities and phrases enables organizations to make confident and accurate judgments, whether they are identifying possible dangers, spotting fraudulent activity, or doing market analysis.
1- File Upload & Data Visualization
In this initial step, we leverage the capabilities of papAI 7 by uploading a text file to gain deeper insights into our data. By harnessing papAI’s advanced analysis tools, we unlock a more detailed perspective of our input data.
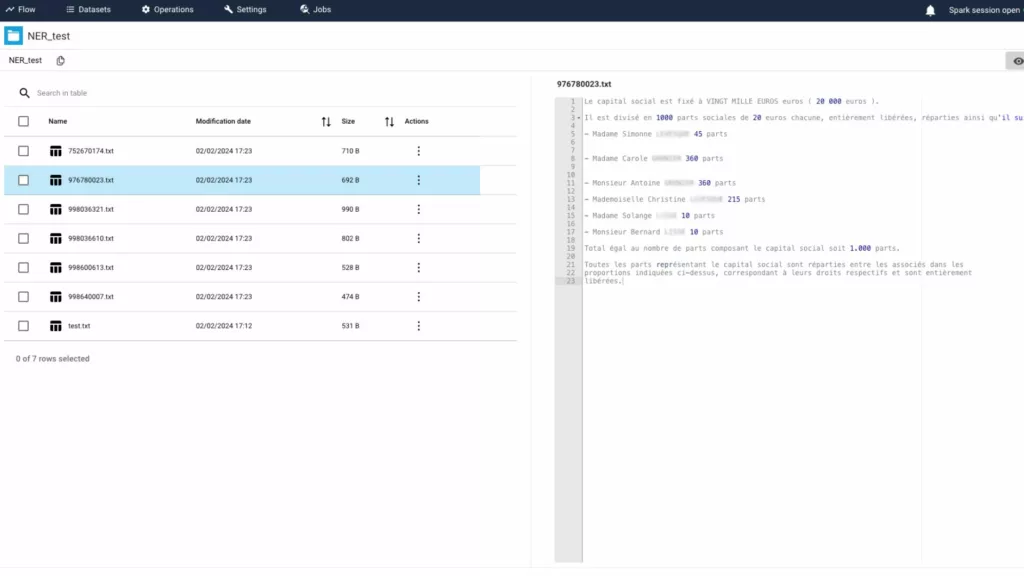
2- Entity Labeling & Recognition
In this second step on papAI 7, we engage in the process of selecting specific entities within our text data for labeling and extraction. Through advanced named entity recognition techniques, papAI identifies and extracts key information such as names of people, organizations, locations, dates, and more. This step lays the foundation for deeper analysis and insights into our data.
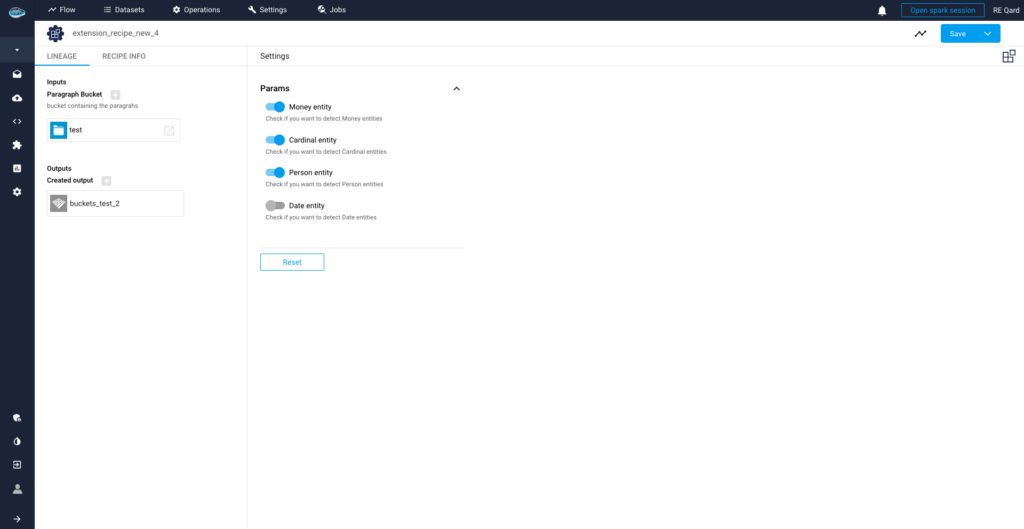
3- Pre-Relationship Assessment Stage
During this pivotal step on papAI 7, we focus on examining the lists of entities that have been extracted from the text data. Through evaluation and analysis, we ensure the accuracy and relevance of the identified entities before proceeding to establish relationships between them. This phase serves as a critical quality control checkpoint, ensuring the integrity and reliability of subsequent analyses and insights derived from the data.
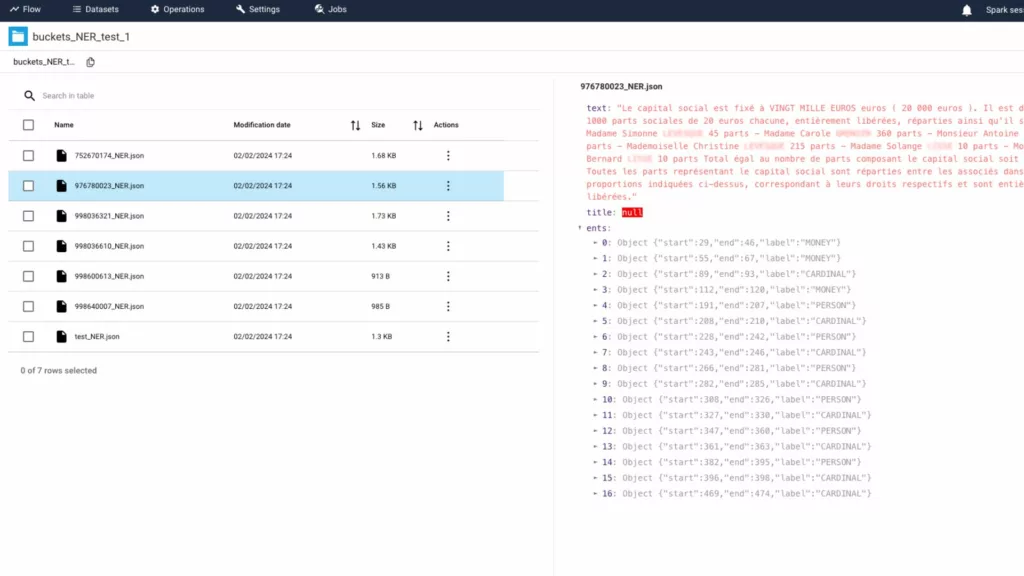
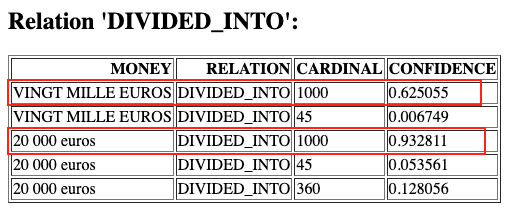
4- Highest Probability Result Extraction
In this concluding step on papAI platform, we attain our initial results by validating the relationships between entities extracted from the text data. Through meticulous validation processes, we identify and prioritize relationships with the highest probability, ensuring the reliability and accuracy of our extracted data.
By selecting values with the highest probability, we obtain the most dependable results, facilitating informed decision-making and strategic insights based on the analyzed data.

Create Your Own Custom NLP Tool to Examine Your Different Text Files with papAI 7
Using advanced techniques including sentiment analysis, entity identification, and topic modeling, papAI helps users to better comprehend a variety of text data sources, extract pertinent information, and spot trends.
The opportunities for data-driven innovation and decision-making are unlimited when using papAI’s natural language processing (NLP) capabilities to analyze financial records, customer reviews, or social media postings.
Are you interested in using specialized NLP tools to examine your text documents? To learn more about how papAI 7 can revolutionize your data analysis procedures, schedule a demo with a Datategy AI expert now.
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language in a meaningful way. It combines techniques from computer science, AI, and linguistics to process large volumes of textual data efficiently.
- Tokenization: Splitting text into smaller units (tokens) such as words or phrases for easier analysis.
- Stemming and Lemmatization: Reducing words to their root forms to normalize variations and improve text interpretation.
- Sentiment Analysis: Identifying the emotional tone of text to understand user opinions and feedback.
- Text Classification: Categorizing documents based on predefined labels, useful in spam detection, topic classification, and document organization.
- Enhanced Efficiency: Automates large-scale text analysis, reducing manual effort and speeding up processing.
- Higher Accuracy: Uses advanced linguistic models to extract relevant insights, improving decision-making.
- Multilingual Support: Enables organizations to process documents in multiple languages, facilitating global operations.
- Compliance & Risk Management: Identifies regulatory risks and compliance issues automatically, helping businesses mitigate legal risks.
- Data Quality & Quantity: NLP models require large, high-quality datasets for training, but businesses often struggle with inconsistent or unstructured data.
- Multilingual Complexity: Supporting multiple languages and dialects requires additional model training and optimization.
- Interpretability & Explainability: Many NLP models, especially deep learning-based ones, function as “black boxes,” making it difficult to explain their decision-making process. This poses challenges in regulated industries.
- Scalability & Costs: Implementing NLP at scale requires significant computing resources and expertise, which may be a barrier for some organizations.
Interested in discovering papAI?
Our AI expert team is at your disposal for any questions

Why is Deployment Speed the New 2026 AI Moat?
Why is Deployment Speed the New 2026 AI Moat? The...
Read More
We Don’t Just Build AI, We Deliver Measurable Impact
We Don’t Just Build AI, We Deliver Measurable Impact Join...
Read More
AI’s Role in Translating Complex Defence Documentation
AI’s Role in Translating Complex Defence Documentation The defence sector...
Read MoreApplying NLP for Intelligent Document Analysis using papAI 7
Summary

Article Name
Applying NLP for Intelligent Document Analysis using papAI 7
DescriptionExplore how NLP and papAI empower intelligent document analysis, revealing insights and streamlining processes.
Author
hocine ousmer
Publisher Name
Datategy
Publisher Logo